Spying on You from Space
The chest thumping in economics about how big and cool our datasets are is becoming somewhat unbearable. Bigger is not always better. In fact, one of the many reasons why we love the field of statistics is that we don’t have to know everything about everyone, but we can infer information about the larger population based on a small (and hopefully random) sample. Big data were not useful when computers were essentially electrified wooden spoons holding hands being fed code and data on paper punch cards. Now that my current iPhone has a processor 10,000 times faster than the Mac Color Classic I wrote my undergraduate thesis on, there are few computational constraints and the opportunities are endless. I can connect to the Amazon Cluster and run my programs on thousands of computers at the same time. Many of the papers I read using big(ger) data, however, don’t really add a proportional amount of knowledge.

But, last week our former student Marshall Burke at Stanford jointly with the certified genius David Lobell and some colleagues in the Stanford Computer Science department published a paper in Science that still has me giddy. One of the big issues in trying to learn information about households is that you have to ask them questions. And that is really expensive. The 2010 US Census cost $13 billion. The World Bank spends millions on sending surveyors out across the world to learn about incomes, what homes look like, the health status of members of households, etc. Due to constrained budgets, you cannot ask everyone.
But, we are asking too few people, which leads to a devastating lack of knowledge. In the Burke-Lobell paper we learn that between 2000 and 2010, 25% of African countries did not conduct a survey from which one could construct nationally representative poverty estimates and close to half conducted only a single survey. This is problematic, since we are trying to eliminate poverty by 2030. If we don’t know where the poor are, this is going to be hard.
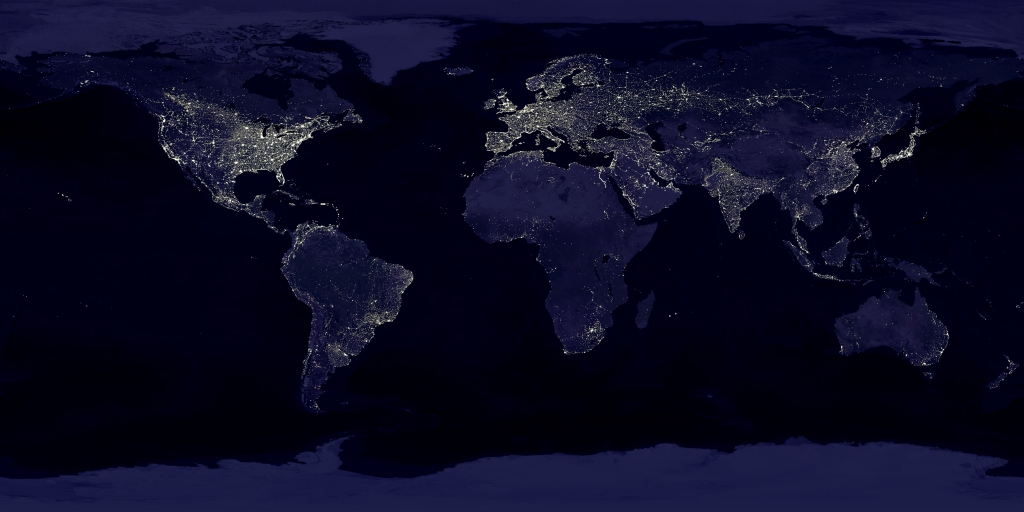
The paper proposes an approach that is likely going to provide high-resolution estimates of poverty at a tiny fraction of the costs of surveys. The authors used the ubiquitous NASA imagery of earth at night, which shows night lights. Night lights are a decent indicator of energy wealth and higher incomes, since without electricity, no streetlights (usually). This is where the rest of us, me included, stopped our thinking. The Stanford brainiacs used the lower resolution night light data and a machine learning algorithm to look for features in the much higher resolution daytime imagery that predict night lights. They did not tell the machine what to look for in the way an econometrician would, but let the computer learn. The computer found that roads, cities, farming areas are features in the daytime imagery that are useful to predict night lights. The authors then discard the night lights data and use the identified features to predict indicators of wealth found in surveys. They show that the algorithm has very impressive predictive power (think Netflix challenge, but for poverty indicators instead of whether you chose the West Wing over the Gilmore Girls).
Once the model is trained, they then use the daytime imagery to predict poverty indicators at a fine level of aggregation covering areas we were totally missing before, and the maps are impressive. If you want to learn more about what they did, they made a video you can watch: https://www.youtube.com/watch?v=DafZSeIGLNE
Satellite imagery has become a rapidly growing source of startups in the energy and retail sector. There are firms tracking ships carrying oil across the seven seas in real-time; there are firms tracking drilling activity at fracking sites; and, there are firms tracking the number of vehicles in shopping mall parking lots. All of these firms treat satellite imagery like the average American treats their TV: We watch the imagery presented to us. What Marshall et al. did here is leagues cooler. They combine two types of satellite imagery with some actual survey data to back out predictions of one of the most important economic indicators – poverty. This product is a game changer. I can’t wait to see the energy economic applications of this method.
Categories
Maximilian Auffhammer View All
Maximilian Auffhammer is the George Pardee Professor of International Sustainable Development at the University of California Berkeley. His fields of expertise are environmental and energy economics, with a specific focus on the impacts and regulation of climate change and air pollution.

Hi Maximilian,
This is a very interesting approach. How does this method estimate population? It can see poverty by geography. Can it also estimate population village by vilage so we can roll up to see how we are doing on our 1 billion goal?
Thanks, Mark