Solar on Every Roof, Electric Vehicles in Every Driveway?
Focus on how distributed energy resources are paid, not on how they improve grid planning.
When Bill Gates started Microsoft he set the goal of “a computer on every desk and in every home”. Up to that point computing had been highly centralized, based around powerful mainframes and “dumb” terminals that were limited to business settings. Gates’ vision largely came to be. Personal computers became widespread in business and home settings and spurred the rapid increase in labor productivity in the 1990s.
California’s tech sector had an outsized role in that evolution. Now the state’s electricity sector could be undergoing a similar decentralization. Over 1.2 million California households and businesses currently produce electricity from their own solar systems. Another million customers have agreed to adjust their electricity demand when called upon by the grid operator through demand response programs. The drivers of the state’s 400,000 registered electric vehicles could participate in similar programs in the future.
Collectively, customer-sited solar, electric vehicles and demand response are referred to as “distributed energy resources”. These are technologies that consumers use, or could in the future use, to do things that have traditionally been done by the centrally managed power grid. This includes producing energy with solar panels and quickly increasing or decreasing demand with smart thermostats or electric vehicle chargers. Small-scale utility-owned generators can also be referred to as distributed energy resources, but in this blog post I’m focused on resources controlled by utility customers.
According to recent California Energy Commission forecasts, a personal computing-style revolution is underway. The agency forecasts that from 2019 to 2030, behind-the-meter solar generation will grow by 260%, customer-sited energy storage will jump 770% and electric vehicle electricity consumption will grow by 370%. The hope is that these distributed energy resources will displace polluting fuels and could even reduce the need for the traditional centralized grid with all of its power plants, wires and other equipment.
In anticipation of these trends, the California Public Utilities Commission (CPUC) has opened a suite of rulemakings to update regulations and to prepare for and enable a more distributed energy future. The rules will govern how the future grid is planned and how much distributed resource owners get paid, or save, for their contributions. Policymakers are exploring a wide range of directions, I’d argue maybe too many. In this blog post I’ll discuss what research to-date suggests as the most promising directions for policymakers to focus.

Lack of Evidence that Distributed Energy Resources Can Improve Grid Planning
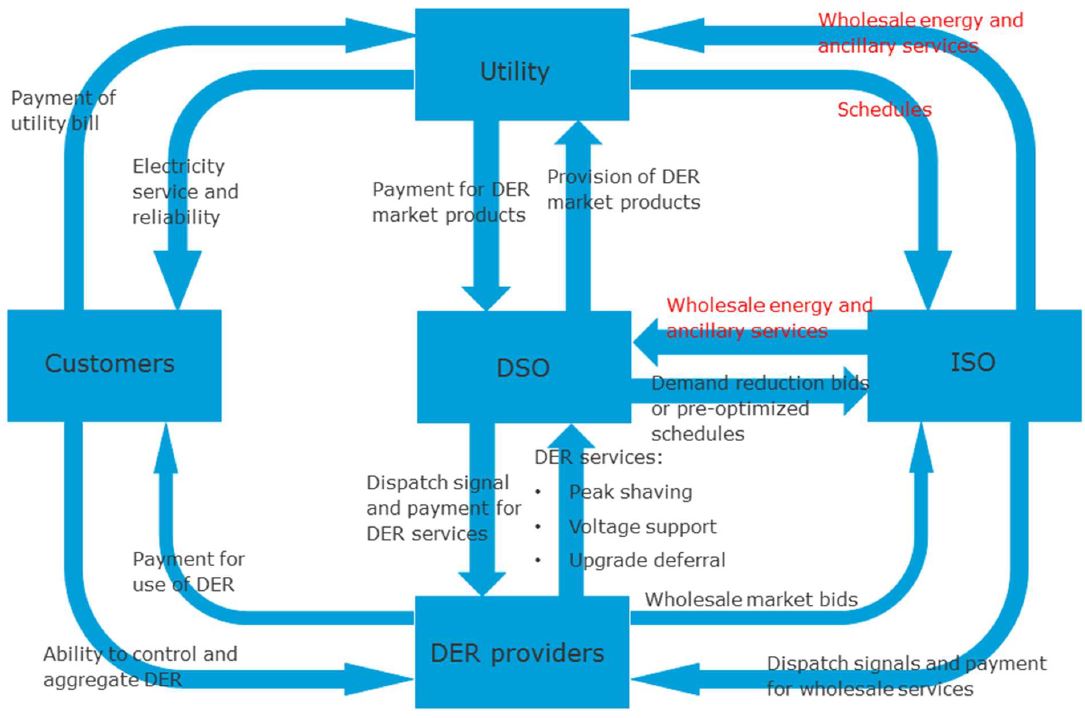
Duncan Callaway and Meredith Fowlie described in a recent blog post how grid costs have been growing rapidly, and surprisingly. The CPUC has launched a new rulemaking focused on finding ways that distributed energy resources can reverse this trend. They will look at new approaches to coordinating investments and operations on the distribution grid. This includes a look at some radical, or innovative, ideas, such as restructuring the utilities and creating independent Distribution System Operators (DSOs). A study commissioned by the CPUC describes the DSO as an entity that would assume responsibility for planning and operations of the local grid from utilities. The DSO would also facilitate markets where distributed energy resources provide circuit-specific demand reductions, voltage support, or defer grid investments.
The vision of the DSO is exciting, but could be complex, time consuming and costly to establish. Policymakers should ask early on whether it’s worth it. Research so far suggests it may not be.
Research by Michael Cohen and Duncan Callaway shows that there are few parts of the grid where distributed solar (the most common type of distributed energy resources) can help defer capital investments. In the vast majority of locations, these resources provide very little value to the distribution grid. If these results hold up over time and more widely (they studied PG&E data) then policymakers should ask whether there are enough benefits to creating a DSO.
New research from Anna Brockway, Jennifer Conde and Duncan Callaway highlights another important dimension of distributed energy resources that would not be easily addressed by a DSO: inequality. They find disadvantaged areas have less capacity to accommodate distributed generation. This raises important policy questions about whether utilities should proactively expand grid capacity in disadvantaged areas so that a distributed energy future unfolds more fairly. Adding inequality reduction as a goal of a DSO would further complicate its difficult task, and could be more easily addressed by regulators through traditional rate cases.
Other potential value creation from distributed energy resources have yet to be studied, and should be. For example, the idea of establishing circuit-specific electricity prices that signal when consumers should use their resources to produce and consume electricity could be studied. But the research to-date does not make a strong case for creating a DSO or focusing on the grid planning benefits of distributed energy resources.
Fixing Compensation
Research makes a strong case that policymakers should take action to change the compensation that renewable energy resources owners receive. Owners of distributed solar receive far more value in bill reductions than they are saving for the system, research shows. The growing number of owners of both distributed solar and energy storage pay utility rates that encourage them to minimize their consumption from the grid, but they receive no extra benefit from injecting energy into the grid at times when it would most benefit others. Drivers considering electric vehicles are faced with excessively high costs for electric fuel. Those that still buy an electric vehicle pay prices that offer little incentive to actively manage when they charge.
Consumers continue to invest in distributed energy resources at a rapid rate, and this will be further encouraged through new federal and state incentives. However, the flawed retail prices that distributed energy resource owners face are not encouraging investments in the resources that would be most beneficial to the environment or the wider grid. Fortunately, the CPUC is looking at some of these issues in current rulemakings and may initiate further efforts soon. The stunning projections for how quickly distributed energy resources could grow underlines how urgent these reforms are.
Keep up with Energy Institute blogs, research, and events on Twitter @energyathaas.
Suggested citation: Campbell, Andrew. “Solar on Every Roof, Electric Vehicles in Every Driveway?” Energy Institute Blog, UC Berkeley, October 11, 2021, https://energyathaas.wordpress.com/2021/10/11/solar-on-every-roof-electric-vehicles-in-every-driveway/
Categories
Andrew G Campbell View All
Andrew Campbell is the Executive Director of the Energy Institute at Haas at the University of California, Berkeley. At the Energy Institute, Campbell serves as a bridge between the research community, and business and policy leaders on energy economics and policy.

Andrew, thank you for giving us a picture of one potential “electricity future”. I’m wondering, however, if the real problem is that our retail electricity prices (at least in IOU California) bear no resemblance to marginal cost. Severin and others have covered this in many other Haas Blogs. Additionally, resiliency of electrical infrastructure and the value/cost of lost load is not properly accounted for in my view—-creating pricing distortions.
The research you point to in your article is telling. In a 21st century where retail electricity sales have been relatively flat, and peak demand has not risen, how is it that electricity rates and distribution CAPEX continues to rise. I’m in the camp of “because that’s the only capex bucket left where IOU’s can ratebase expenditures”. We certainly haven’t seen many IOU dividend reductions over this same period…….
Lastly, and as was previously mentioned by at least one of your commenters, does the evolution of regional DSO’s leave enough “open field” for “traditional utilities”? Or are today’s traditional utilities the DSO’s of the future?
Mr. Dodenhoff wrote: ” In a 21st century where retail electricity sales have been relatively flat, and peak demand has not risen, how is it that ,,, distribution CAPEX continues to rise?” I have four comments:
1. A nefarious desire by PG&E to add to rate base is one possibility.
2. Undergrounding, e.g., to reduce the risk of igniting wildfires, is another possibility.
3. Even in “…a 21st century where retail electricity sales have been relatively flat, and peak demand [as measured on the utility side of the meter] has not risen”, it’s possible that overall regional usage and peak demand have increased. Why? Generation on the customer side of the meter (e.g., by residential solar) has increased, too. For some circuits with residential solar, it seems possible that brief, local cloudiness during local peaks might necessitate beefing up.
4. At PG&E 10 or 15 years ago, before I retired, I was told that (a) some of PG&E’s distribution equipment was set to trip if power flowed from a distribution circuit back to the grid even for a moment, and (b) changing that, to accommodate residential solar, entailed significant capital expenditure. I regret that I cannot cite any report. Perhaps some EE out there can comment?
1. The most apparent explanation with decoupling removing the added revenues from added sales. This problem has been cited nationwide, not just in California.
2. Large scale undergrounding for fire risk hasn’t yet started. That $15B-$40B investment will likely lead to another 10% to 25% increase in rates on top of the 30% that PG&E is proposing through 2026 in its 2023 GRC filing.
3. Statewide demand and loads have remained flat and even declined since 2006. The CAISO August 2020 peak load under 1-in-35 year conditions was still 3,000 MW below the 2017 record peak which just edged out the 2006 peak. Most of the IOU distribution investment has been for “growth” not to accommodate the type of peaking you mention. The fact is that solar output is correlated with daytime peaks–the hottest temperatures happen with the clearest skys.
4. Again, that type of investment has not been mentioned on a large scale in the IOU GRC filings, and replacing a type of circuit breaker doesn’t represent billions of dollars and maybe not even beyond the low hundreds of millions–a blip in current rates.
Hi Mark,
Good and informed answers. I vote for #1….and see #2 as a PG&E s cynical subset of #1. Undergrounding ? I know they ve proposed it for some of their territory, but the risk/reward equation doesn’t work in my opinion. We already have the most expensive electricity in the country.
Andy, I often encounter DER advocates earnestly attempting to relate the distribution of power electricity to the distribution of computing, or the deregulation of the telephone industry.
The comparisons ignores a significant difference: information can be easily, efficiently, and safely transmitted through the air or on low-voltage wiring; power electricity cannot. It requires cables up to 1″ in diameter transferring anywhere from 600 to 500,000 volts. A human standing on the ground who comes in contact with either would be killed instantly. For that reasons and others, grid cabling is required to be installed at minimum heights above the ground; transmission towers and poles must conform to specifications that guarantee stability in storms, and safety for vehicles passing underneath. They require significant investment, whether public or private. If private, the investors who funded it obviously expect its users to pay for access, so they can realize a return on their investment.
As a grid customer with no DER, I have no problem with a neighbor who wants to “go off-grid” and generate his own electricity. I do have a problem with
• cross-subsidizing his share of costs for grid maintenance;
• subsidizing 30% of his costs with a solar array investment tax credit;
• being forced to buy his electricity at retail rates, when his array and those of others are only making our shared resource less reliable;
• bearing the burden of his carbon emissions on cloudy days, or when he buys a home generator to make up for his array’s shortcomings;
Show me a home with solar panels and I’ll show you an owner who’s less environmentally-responsible than arrogant. “I’m doing my part,” he would say, and he would be right: he’s doing his part to save himself money. Nowadays, IMO, lowering carbon emissions and maintaining access to electricity for all entails quite a bit more than that.
I’m getting 100% of my Tesla Model 3 energy in Austin from some small solar panels see https://egpreston.com/solarpanels.jpg I match the charging rate with the solar output. Works great. I recommend everyone try to power their transportation using their own solar power rather than grid power. My off grid system cost only $1800 including the inverter. It does not rely on a large battery like the Power Wall does. Solar power goes right to the car in real time.
Sorry, your first paragraph is entirely in error. The goal of Bill Gates was Microsoft on every computer sold, not a computer on every desk. He achieved this goal through a cunning, and unique for its time, licensing agreement with IBM and others. The agreement stipulated that Microsoft be paid a licensing fee for every computer sold, regardless of whether Microsoft software was on the computer or not. Manufacturers felt compelled to install the software, since they had to pay the fee anyway. That’s how the world got stuck with the clunky OS that was MS-DOS and later Windows.
I’m sure I’m not the only home with too much shade to go solar. I did have one salesman say his panels didn,t require sun.
And before you suggest I cut the trees down that’s not green either
Thank you for a clear and interesting article. One question: In a Distribution System Operator Model in California, what would be the role of Community Choice Aggregators?
Mark
In a world with DSOs, CCAs or other local LSEs could have several roles. They would be able to continue to acquire grid scale resources for local needs (the munis have demonstrated the success of that model), or since they can be closely intergrated with local governments, they can manage front of the meter and behind the meter resources, particularly through building codes and ordinances. They also don’t have significant impediments to incentivizing into both the EV market place and electrification of home appliances.
The better question is what role will a centralized large scale utility that experiences organizational diseconomies of scale have?
“The better question is what role will a centralized large scale utility that experiences organizational diseconomies of scale have?”
Your attempt to blame-shift the absence of economies of scale at your hodgepodge of DSOs/CCAs/V2Gs on centralized utilities, with abundant economies of scale, is duly noted. “It’s not that we’re duplicating effort, hardware, and organizational resources a thousand times over – it’s that professional engineers at utilities have no experience dealing with such incompetence.” Is that the takeaway?
I’m not really able to disentangle your comment. However, I’ll cite a study done Christensen & Associates for the CPUC’s Office of Ratepayer Advocates, presented in the 1999 PG&E General Rate Case and cited in the decision in that case, that showed that the optimal size for an electric utility was about 500,000 customers compared to the then-4 million customers that PG&E had. That’s the basis for my statement.
Others also thinking along this line, seeing the changing environment for transmission oriented utilities:
https://www.utilitydive.com/news/electric-co-ops-must-heed-the-lessons-of-kodak-and-others-in-pushing-to-ove/606806/
“…that showed that the optimal size for an electric utility was about 500,000 customers…”
Optimal for whom? One electric utility with 16 million customers has unlimited economies of scale compared to 32-500,000 customer ones, with conflicting priorities, duplicative assets, and duplicative administrative costs. If our goal is to afford everyone in society equal access to electricity, and a truly independent Public Utilities Commission is there to oversee it, regulating one entity is far less costly and cumbersome.
Economies of scale of course, are less optimal for solar & wind profiteers, which rely on selling solar panels in the millions of square meters and wind turbines numbering in the thousands to make their vast ends meet. If our goal is to enrich unregulated LSEs and stimulate our economy – to create thousands of unnecessary extra jobs and high-profile infrastructure projects at the cost of electricity customers – then distributed generation is the way to go. Whatever the “study” of a research-for-hire marketing group might have to say about it.
Optimal as in lowest cost per kWh served–the most basic metric. Economies of scale are not infinite, and as I mentioned, organizational diseconomies eventually overwhelm technological economies. Christenson and Associates (out of Madison WI) have done a number of studies along these lines. That means that smaller utilities will afford us lower rates for everyone.
As to the CPUC being truly “independent” hasn’t happened nor will it ever happen–just look at the revolving door of utility executives and commissioners.
“Optimal as in lowest cost per kWh served–the most basic metric.”
Your study identifies the lowest cost/kWh as a function of the size of a single utility’s customer base. It doesn’t compare a utility’s average cost/kWh to the same average cost/kWh served by hundreds of independent entities – CCAs, DSOs, HOAs, etc. There are no economies of scale gained by duplication of effort and assets – only waste.
“…organizational diseconomies eventually overwhelm technological economies.”
Please explain exactly what “organizational diseconomies” exist in a utility, like PG&E, which aren’t multipled ten- or one-hundred-fold by hundreds of DSOs or CCAs serving the same 16 million customers (?).
And now the data on a PC has returned back to being stored centrally, in the cloud, on Amazon web services, or MS or another of the other big data storage companies. Readily accessible but less distributed.
I ain’t buying an electric vehicle until they stop selling gasoline